There is a pattern I keep seeing across engineering organizations, and it predates agents entirely. TPMs and PMs produce BRDs, PRDs, and backlog items aimed at stakeholders, leadership, or process compliance, and in doing so they consistently miss their actual core audience: the makers. The engineers and agents who have to turn those documents into working software.
The tools problem gets all the attention. MCP servers, function calls, orchestration frameworks. But a well-connected agent handed a vague PRD will fail for the same reason a well-intentioned engineer handed the same document will spend three days in clarification meetings. The bottleneck is not the tooling. It is the quality of the input.
“most agent failures are not model failures anymore, they are context failures” – Jin Tan Ruan, Context Engineering in LLM-Based Agents (2024)
The Problem Is Not New
Feeding an agent the right context (the right data, ontology, and goals) is structurally identical to how we should have been delivering information to human developers all along. The same failure modes apply:
- A developer joins a project and spends two weeks piecing together intent from scattered Jira tickets, Slack threads, old PRs, and Word documents nobody updated.
- An agent joins a task and spends tokens (which means money and latency - see Tokenomics: The Allocation of Scarce Resources in Agentic AI) reconstructing the same picture from the same scattered sources.
The medium changed. The problem did not.
Three Principles That Matter
Transference: The ability to efficiently communicate ideas to the right executor. Whether that executor is a human or an agent, the sender bears responsibility for packaging the message well. Most organizations are bad at this. Institutional knowledge lives in people’s heads, not in systems.
“We can know more than we can tell.” – Michael Polanyi, Personal Knowledge (1958)
Focus and Flow: Productive work requires limited, intentional capability surfaces. An agent given fifty tools and no clear task definition performs worse than one given five tools and sharp context. The same is true for a developer handed a sprint with twenty tickets and no prioritization. Constraint is a feature.
Mihaly Csikszentmihalyi’s research on flow states identified the conditions under which people do their deepest, most absorbed work: clear goals, unambiguous feedback, and a challenge matched to skill level. Critically, flow requires that the cognitive environment be free of unnecessary friction: the work itself is the challenge, not the overhead of navigating ambiguity. A developer who must stop to hunt for context (which Jira ticket has the actual decision? which Confluence page is current? who is the right person to ask?) cannot enter flow. The preconditions were broken before the work began. An agent in the same situation burns tokens reconstructing what should have been handed to it cleanly, rather than doing the actual task it was given.
Data Proximity: Cohesive information should be centralized, not scattered across Git, Jira, GitHub Issues, documentation wikis, meeting recordings, and Slack threads. The cost of retrieval is not just latency; it is lost coherence. When context has to be assembled from many sources, something always gets dropped or misread.
Distributed systems design has a well-established rule: move computation to the data, not data to the computation. When data must travel across the network to reach the process that needs it, you pay in latency, bandwidth, and consistency risk. This is why Hadoop co-locates map tasks with the HDFS blocks they process, why CDNs cache at the edge, why databases use indexes instead of full scans. The organizational equivalent of “data far from compute” is knowledge scattered across a dozen disconnected tools. An agent or developer assembling context from twelve sources is operating under the distributed systems worst case: no locality, no caching, no consistency guarantees, no defined schema. The repo-as-SSOT is the data-local design. The context is already where the work happens.
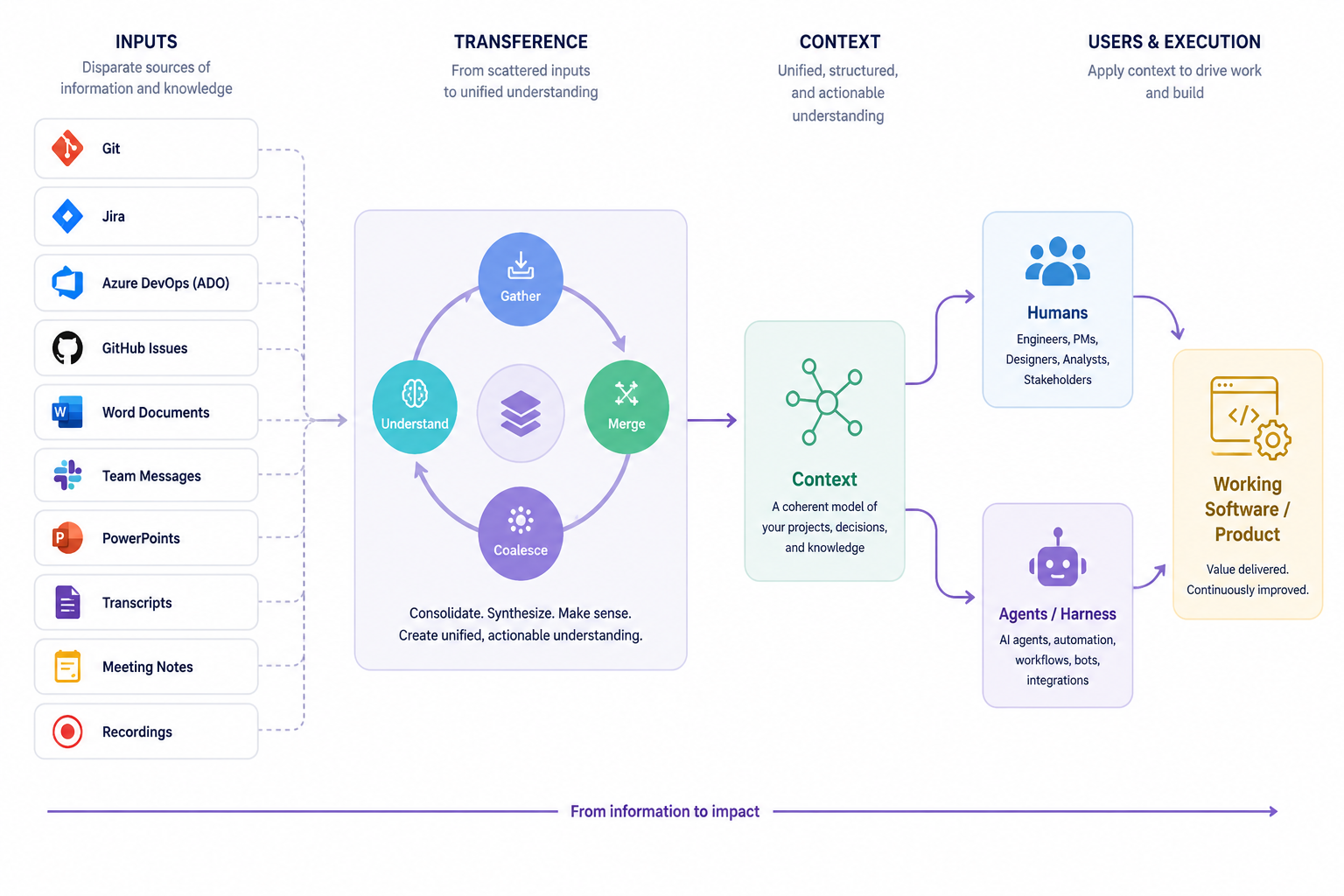
From Information to Impact
The diagram maps the full flow:
| Stage | What Happens |
|---|---|
| Inputs | Disparate sources: Git history, tickets, documents, transcripts, recordings |
| Transference | Consolidate, synthesize, and create unified, actionable understanding |
| Context | A coherent model of your project’s decisions and knowledge |
| Execution | Humans and agents apply that context to ship working software |
The gap that breaks most teams is between Inputs and Context. The raw material exists. The synthesis does not.
This Is a Skills Gap, Not a Tools Gap
The people who create information artifacts (PMs writing specs, engineers writing ADRs, leads running standups) often lack empathy for the end consumer of that information. They write for themselves, not for a reader who has no ambient context. When the reader is an agent operating on a strict token budget, that failure is immediate and measurable.
This pattern is not new. The Standish Group’s CHAOS Report (tracking software project outcomes since 1994) found that the top reason projects succeed is a clear statement of requirements, and the top reason they fail is incomplete or ambiguous ones. Decades later, the same deficit now shows up as failed agent deployments.
This is not a criticism. It is a skill most organizations never needed to develop explicitly because human developers are good at filling gaps with social inference. Agents cannot do that. They will either hallucinate to fill the gap or surface a retrieval failure you will misread as a model problem.
The forcing function is useful. Building the discipline to produce clean, structured, self-contained context artifacts makes the whole organization sharper, for agents and for the next human engineer who joins the team.
Gall’s Law: Complex Systems Don’t Get Fixed, They Get Replaced
John Gall wrote in Systemantics (1975):
“A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start all over again, beginning with a working simple system.”
Look at the typical organization’s information architecture: Jira for tickets, Confluence for docs, Slack for decisions, GitHub Issues for bugs, SharePoint for specs, Notion for team notes, Loom recordings nobody watches, email threads with the actual context buried in the seventh reply. No one designed this. It accumulated. And by Gall’s Law, it will never reliably work as a context source for humans or agents, because it is a complex system that did not evolve from a simple working one. It was assembled from disconnected parts, each reasonable in isolation, collectively incoherent.
The instinct when this fails is to add more: a RAG pipeline to index all the sources, a knowledge graph to link them, an AI assistant to summarize the Slack threads. That is patching a complex system. Gall’s Law says it won’t hold.
The alternative is to start over with something simple that works: the repository. Not because repositories are magic, but because a single authoritative source with low ceremony and high signal is a simple system. Commit messages, ADRs, a well-maintained CLAUDE.md: these are small, composable, version-controlled artifacts. When you need more, you add it deliberately. The system evolves rather than accumulates.
This is the path Gall describes. An org that disciplines itself to keep the repo as the canonical source of truth has a working simple system. It can grow. The org that tries to integrate twelve tools into a coherent context layer is starting from the wrong place, no matter how good the integration is.
The Repository as Single Source of Truth
One practical anchor: the repository. If your project’s goals, decisions, constraints, and current state live in the repo (in CLAUDE.md, in well-structured ADRs, in commit messages that explain why rather than what), then any executor (human or agent) can be brought up to speed quickly and reliably.
This is not a new idea. It is what good engineering teams have always tried to do. Agents just make the cost of not doing it visible in real time.
The opportunity is real. Most organizations have a significant gap between the information they produce and the refined clarity that both agents and humans actually need to do their best work. Closing that gap is the leverage point.
References
Recent
- Jin Tan Ruan, “Context Engineering in LLM-Based Agents” (2024)
- Digital Applied, “Why 88% of AI Agents Fail Production” (2024)
- Tobias Lutke (Shopify CEO) via Kubiya AI, “Context Engineering for Reliable AI Agents” (2025)
- Andrej Karpathy, “Software 2.0” (2017)
- Jeffrey Dean & Sanjay Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters” (Google, 2004), foundational statement of the “move computation to data” principle
Foundational
- Mihaly Csikszentmihalyi, Flow: The Psychology of Optimal Experience (1990)
- Michael Polanyi, Personal Knowledge (1958)
- Melvin Conway, “How Do Committees Invent?” (Datamation, 1968)
- Horst W. J. Rittel & Melvin M. Webber, “Dilemmas in a General Theory of Planning” (Policy Sciences, 1973)
- Frederick P. Brooks Jr., The Mythical Man-Month (1975)
- John Gall, Systemantics: How Systems Really Work and How They Fail (1975)
- The Standish Group, CHAOS Report (1994)



